




The News
Reasoning models are now supposed to be the cream of the crop when it comes to accuracy, but that isn’t necessarily the case for the latest buzzy AI.
DeepSeek’s R1 model makes up answers at a significantly higher rate than comparable reasoning and open-source models, according to enterprise AI startup Vectara, which tested R1 and others on its own hallucination-measuring model.
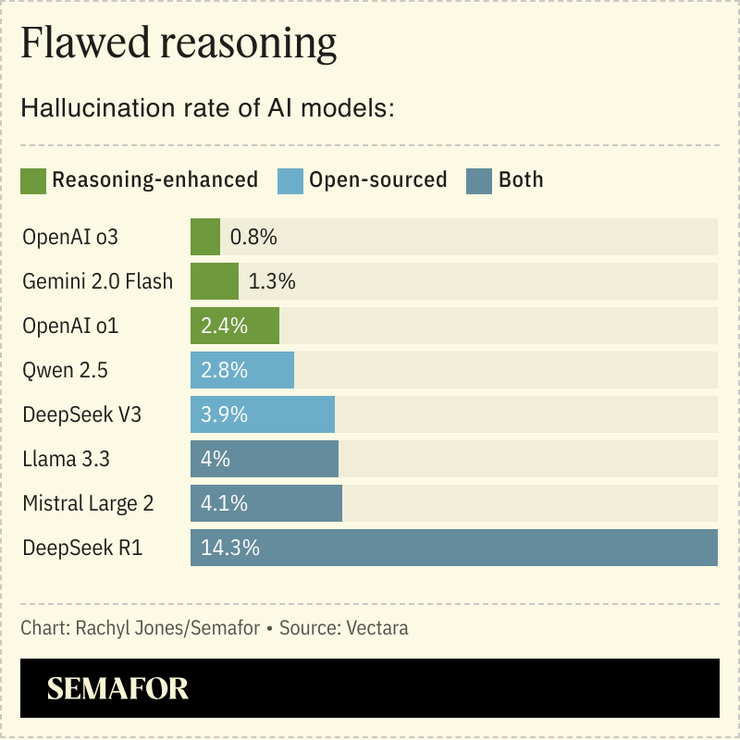
Closed reasoning models from OpenAI and Google hallucinated the least, with Alibaba’s Qwen performing the best out of the crew with part of their code publicly available. DeepSeek’s V3, which R1 was built on, outperformed its successor in accuracy by more than three times.
Reasoning engines are still, well, learning, so the scores will likely get better over time. But reasoning capabilities alone aren’t the cause for increased hallucinations. Rather, it’s fine-tuning the model once it’s built, said Vectara’s head of developer relations Ofer Mendelevitch. “When you train a model for a capability like reasoning, you have to make sure you maintain a lot of other capabilities,” he told Semafor. “DeepSeek didn’t do as good of a job on that, and they will fix it soon, I expect.”
Notable
- Vectara’s test puts numbers to subjective reports about DeepSeek’s propensity to hallucinate, including that of Wired writer Reece Rogers, who spent a few hours testing it and detailed his opinions last week. In addition to hallucinations, Rogers noted moderation issues that persist despite DeepSeek’s advancements in training cost and efficiency. What training data was used also remains a question, but Rogers called it “a major disruptor for US-based AI companies.”